Motivation
The JAM Stack and Serverless are two trends in web development that have a lot going on right now. One of the most common thing to do for a web developer is to create a website with a CMS. Static sites in themselves follow the serverless paradigm of infinite scalability, pay-per-use, and no-touch operations. But we lack an all-round CMS with the same properties.
Wordpress can be used as a headless CMS for modern front-ends, but the old giant is still not ready for more than a few use cases. There are managed CMS-es such as Contentful and Cosmic. These are good products, but are expensive for many users. Furthermore, they are not open source which entails some drawbacks such as not being very flexible.
Strapi is a leading open source headless CMS. While it's relatively new, it is popular, which means they really fill a need in the market. I have many complaints about Strapi, but they are, as far as I see it now, the best option for a general open source CMS.
One drawback even with Strapi is that you need to host it yourself. While it's easy to spin up a server with a database, you have to be worried about scaling it. Even for hobby projects which will probably never have to scale, I feel uncomfortable knowing I might have to get my hands dirty with scaling a database and all that.
Strapi is not made to be serverless. It is, however, possible to shoehorn a Strapi application onto AWS Lambda with the Serverless framework. Since AWS also has a MySQL compatible serverless database in Aurora, we might be able to create an infinitely scalable Strapi that requires very little ops, and costs nothing when not used.
What is serverless?
It has little to do with servers.
- Infinitely scalable The infrastructure can handle spikes and sudden growth is use without problem.
- No touch operations Not only is it scalable. Scaling does not require any effort. You don't manually add or remove instances. You don't write scripts to automatically do that stuff. It's taken care of in the infrastructure. You don't shut things down at night or in weekends to save money because you don't need to. You don't worry about scaling because you know it does so by itself.
- Pay-per-use You only pay when things are being done. Costs are predictable and follow a smooth, linear curve. No execution means zero cost.
Set Up Strapi
We start by setting up Strapi locally. We roughly follow the official quick start guide for Strapi 3.1.
yarn create strapi-app sls-strapi --quickstart
This will create a basic Strapi app with the file based database SQLite in the sls-strapi folder. If successful, Strapi will run on http://localhost:1337.
While we won't use this instance of Strapi with the SQLite database, you should make at least one content type in Strapi either through the content type builder or by adding a content type in the api/ folder. I will create a content type called page with a single field called title. Make the content type and wait for the server to restart.
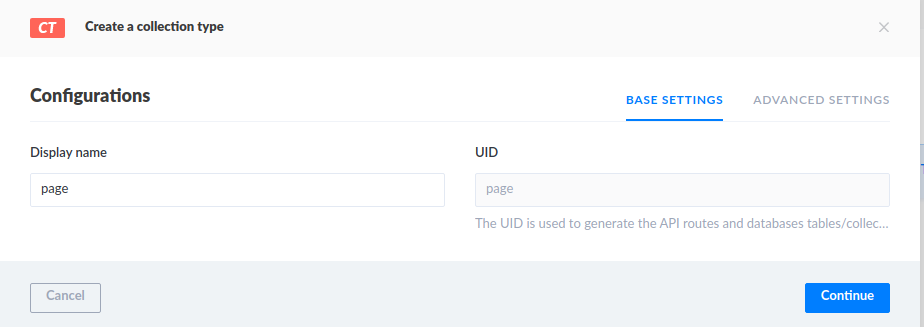
Add a single item to the collection, then test that it works by getting http://localhost:1337/pages. You will get a 403 FORBIDDEN message, as we need to allow unauthenticated users read access to the collection.
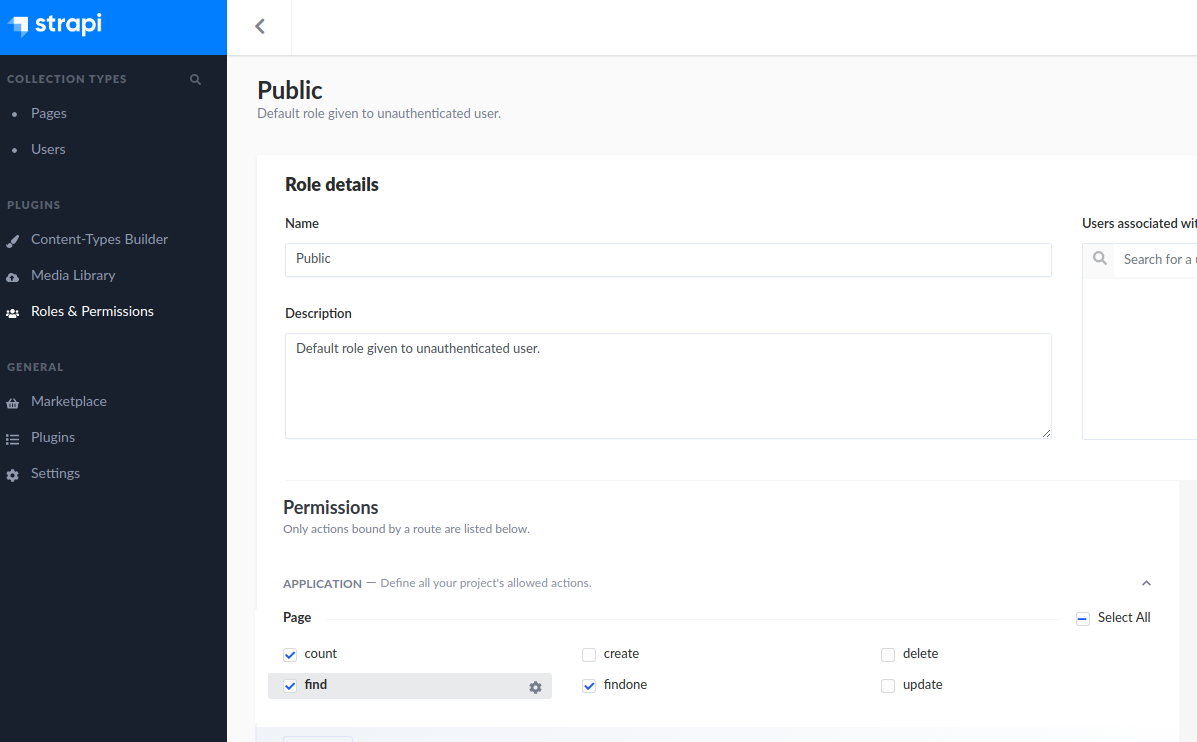
Go to Roles & Permissions, edit the Public group and add permissions to read. http://localhost:1337/pages should now respond with your single page item.
We will come back to configuring Strapi for our serverless needs later.
Set up Serverless
We will add some Serverless config in the same folder as our Strapi app. If you're not familiar with Serverless, you should perhaps try to deploy a simple Express app on Amazon Web Services (AWS) first, just to get some idea of how it works. To get started, check out the official AWS quick start guide.
We install some packages and create a serverless.yml config and a app.js file to get started.
yarn add -D serverless-offline
yarn add serverless-http
serverless-http is an amazing plugin that makes it trivial to run any Node server as a Lambda function. Koa, which Strapi uses, is also supported.
serverless-offline is a well-made plugin that lets you run Serverless apps locally. It works well with serverless-http and even simulates API Gateway, which is a layer in the AWS cloud all http requests go through.
TIP Use a profile in your Serverless config with AWS credentials.
| service: sls-strapi | |
| provider: | |
| name: aws | |
| runtime: nodejs12.x | |
| profile: <your-aws-profile> | |
| logRetentionInDays: ${self:custom.vars.logRetentionInDays, 1} | |
| environment: | |
| ADMIN_JWT_SECRET: "Just using dummy" | |
| package: | |
| exclude: | |
| - ./** | |
| include: | |
| - node_modules/** | |
| - api/** | |
| - config/** | |
| - extensions/** | |
| - plugins/** | |
| - package.json | |
| - app.js | |
| functions: | |
| api: | |
| handler: app.handler | |
| memorySize: 1024 | |
| timeout: 24 | |
| events: | |
| - http: | |
| path: / | |
| method: ANY | |
| cors: true | |
| - http: | |
| path: /{any+} | |
| method: ANY | |
| cors: true | |
| plugins: | |
| - serverless-offline |
| const startStrapi = require("strapi/lib/Strapi"); | |
| const serverless = require("serverless-http"); | |
| module.exports.handler = async (event, context) => { | |
| if (!global.strapi) { | |
| console.log("Cold starting Strapi"); | |
| await startStrapi({ dir: __dirname }).start(); | |
| } | |
| const handler = serverless(global.strapi.app); | |
| return handler(event, context); | |
| }; |
You should now have app.js and serverless.yml in your root directory.
Before we try it, update the database config in config/database.js, so that the storage path for SQLite in the cloud is in the writeable /tmp directory.
| // config/database.js | |
| const getDatabaseConfig = ({ env }) => { | |
| if ( | |
| env("IS_OFFLINE", null) === "true" || | |
| env("LAMBDA_RUNTIME_DIR", null) === null | |
| ) { | |
| // In local simulated Lambda or normal Strapi | |
| return { | |
| connector: "bookshelf", | |
| settings: { | |
| client: "sqlite", | |
| filename: env("DATABASE_FILENAME", ".tmp/data.db"), | |
| }, | |
| options: { | |
| useNullAsDefault: true, | |
| }, | |
| }; | |
| } else { | |
| // In Lambda on AWS | |
| return { | |
| connector: "bookshelf", | |
| settings: { | |
| client: "sqlite", | |
| filename: env("DATABASE_FILENAME", "/tmp/data.db"), | |
| }, | |
| options: { | |
| useNullAsDefault: true, | |
| }, | |
| }; | |
| } | |
| }; | |
| module.exports = ({ env }) => ({ | |
| defaultConnection: "default", | |
| connections: { | |
| default: getDatabaseConfig({ env }), | |
| }, | |
| }); |
It should now be possible to run Strapi as a Serverless app. Test it locally by executing
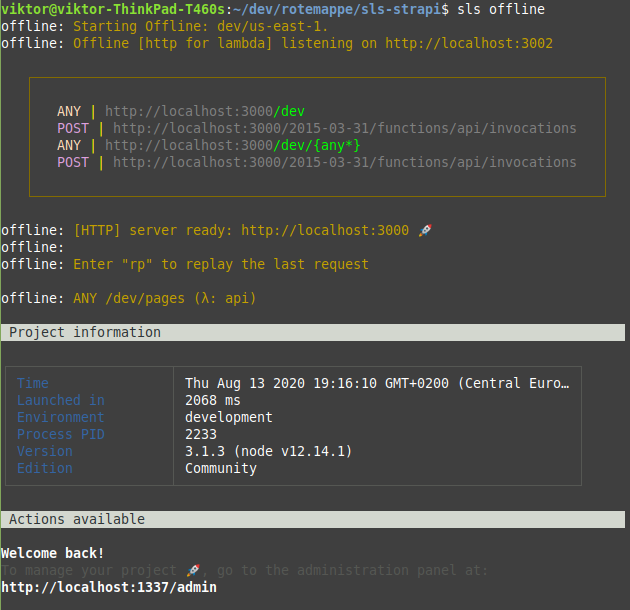
sls offline
This will start the serverless-offline server, but Strapi won't start until you visit an endpoint. Go to http://localhost:3000/dev/pages. If you get a 200 OK with the one page you created before, everything works as it should. The first response might be a bit slow, as the Strapi server takes some time to boot, but subsequent requests will be fast.
Serverless will add a /dev prefix to your URL path, and we need to configure Strapi to work around this later. This is a feature of API Gateway, and not easy to get around without using a custom domain.
Now that we have it working locally, maybe we should try to deploy it to the cloud just to see that everything works as it should there too. Let Serverless deploy it with:
sls deploy --verbose
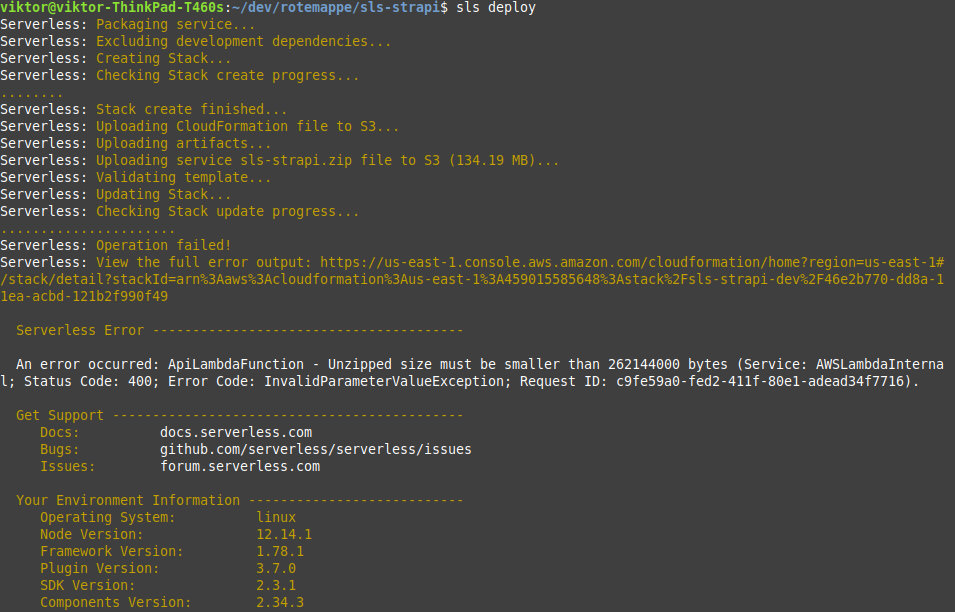
That did not work. The size of our application is way too large for Lambda. This is a common problem when attempting to run applications that are not at all designed for Lambda, in Lambda.
Fortunately, it is quite easy to divide the Strapi monolith into a frontend and backend. Our plan is to host the frontend as a static website (which can practically be hosted anywhere), and the backend as a Serverless app in AWS Lambda.
Trimming Strapi
First, let's follow the official guide for running the admin part of Strapi separately, with some (maybe dirty) tricks to make it work well with our /dev path prefix.
Edit the config of config/server.js to disable the admin panel, and take care of the path prefix.
| // config/server.js | |
| // This config is used both in `strapi build` and `strapi start`. | |
| // So if we have a path prefix to the api, such as /dev or /v1, | |
| // we need to use env variables to configure, as Strapi doesn't | |
| // support path prefixes automagically. | |
| module.exports = ({ env }) => { | |
| let url = "<Insert Lambda endpoint url here after deploy.>"; | |
| // Check if running in serverless-offline | |
| if (env("IS_OFFLINE", null) === "true") { | |
| url = "http://localhost:3000/dev"; | |
| } | |
| return { | |
| host: env("HOST", "0.0.0.0"), | |
| port: env.int("PORT", 1337), | |
| url, | |
| admin: { | |
| serveAdminPanel: false, // No admin panel | |
| autoOpen: false, | |
| url: "/", | |
| auth: { | |
| secret: env("ADMIN_JWT_SECRET", "Insert random string as env variable in production"), | |
| }, | |
| }, | |
| }; | |
| }; |
We will also edit the build command in package.json to run a bash script after the normal build.
// package.json
{
...
"build": "strapi build && ./scripts/post-build.sh",
...
}
Create a script called post-build.sh in a new folder called scripts/. Make it executable with:
chmod +x scripts/post-build.sh
| # scripts/post-build.sh | |
| #!/bin/bash | |
| echo "post-build.sh – moving assets of frontend build to dev/ folder." | |
| mkdir $PWD/build/dev | |
| find $PWD/build/ -type f -print0 | xargs -0 mv -t $PWD/build/dev | |
| mv $PWD/build/dev/index.html $PWD/build |
The script simply moves the bundle files in build/ to a sub folder called /dev which fixes the issue with our path prefixes.
Build the admin panel with:
IS_OFFLINE=true yarn build
Verify that the current setup works by starting the serverless-offline app with sls offline, and then serve the frontend as a separate static site.
You can serve the frontend with
npm i -g serve
serve build/
Go to http://localhost:5000 and check that Strapi still works. Remember to run sls offline in the background.
It may be boring to move slowly and double check everything. One thing I've learnt using Serverless and AWS Lambda is that you will spend hours debugging the most trivial things and cryptic error messages if you don't double check and isolate everything at every step.
If you can still use the Strapi admin, everything is going well.
The size of our code is still not small enough to be used in Lambda, so we need to trim more. Let's explore node_modules.
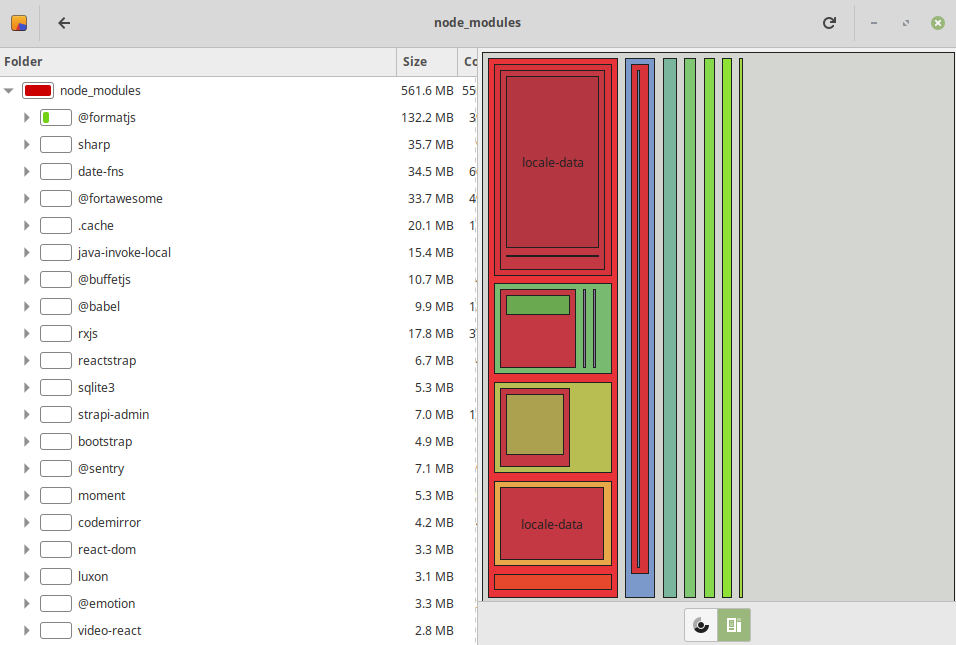
We see node_modules is a whopping 561 MB. We also see a lot of fat packages that are definitely only for frontend use, such as those containing "react", "fortawesome", or "bootstrap". We also see that some locale-data, which is just translations, use most space of all.
It would be great if Strapi automagically removed all frontend stuff from node_modules when we run the backend on a separate server, but I don't know of any such functionality. We will therefore manually delete some excessive packages with some simple commands we put in a bash script aptly called trim-node-modules.sh.
| # scripts/trim-node-modules.sh | |
| #!/bin/bash | |
| echo "trim-node-modules.sh" | |
| du -hs node_modules/ | |
| node-prune # https://github.com/tj/node-prune | |
| find $PWD/node_modules -maxdepth 1 -type d -name "*react*" -exec rm -rf {} + | |
| find $PWD/node_modules -type d -name "locale-data" -exec rm -rf {} + | |
| find $PWD/node_modules -type d -name "*webpack*" -exec rm -rf {} + | |
| find $PWD/node_modules -type d -name "*proptypes*" -exec rm -rf {} + | |
| find $PWD/node_modules -type d -name "*jquery*" -exec rm -rf {} + | |
| find $PWD/node_modules -type d -name "*bootstrap*" -exec rm -rf {} + | |
| find $PWD/node_modules -type f -name "*.css" -exec rm -rf {} + | |
| find $PWD/node_modules -type f -name "*.jsx" -exec rm -rf {} + | |
| rm -rf $PWD/node_modules/font-awesome/ $PWD/node_modules/styled-components/ $PWD/node_modules/rxjs/ $PWD/node_modules/@formatjs/ $PWD/node_modules/codemirror/ $PWD/node_modules/core-js/ $PWD/node_modules/draft-js/ $PWD/node_modules/popper.js/ | |
| rm -rf $PWD/node_modules/@sentry/ $PWD/node_modules/bootstrap/ $PWD/node_modules/@buffetjs/ $PWD/node_modules/highlight.js/ $PWD/node_modules/@fortawesome/ | |
| rm -rf $PWD/node_modules/aws-sdk | |
| du -hs node_modules/ |
Install a neat tool called node-prune first, which automatically removes files that are certainly unnecessary, such as Readmes etc. Get it done with:
npm i -g node-prune
chmod +x scripts/trim-node-modules.sh
./scripts/trim-node-modules.sh
That should reduce the size of node_modules to around 287MB without losing anything we need for the backend.
Finish this step by successfully deploying with:
sls deploy --verbose
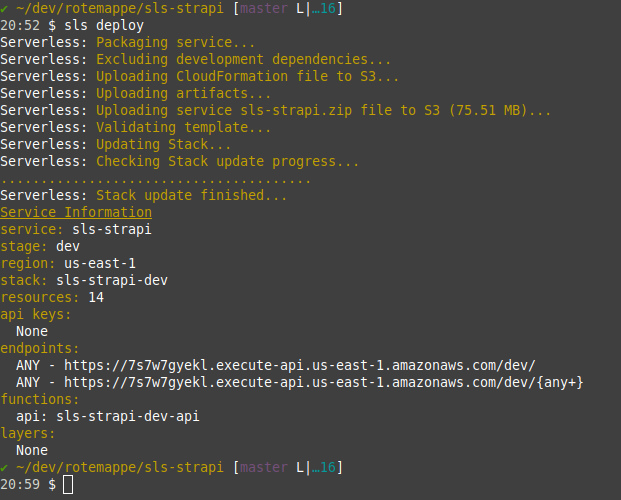
Stack update finished... 🚀
That's what we want to see. The backend is now available online, and you can check it by visiting the generated endpoint (https://7s7w7gyekl.execute-api.us-east-1.amazonaws.com/dev/ for me).
Our database is not at all suitable for Lambda, as it's an SQLite db where the data is stored in the local filesystem which can reset between Lambda invocations. However, it should work for demonstration purposes.
Check your logs with:
sls logs --function api --tail
Update config/server.js with the newly generated endpoint.
// config/server.js
// ...
let url = "https://7s7w7gyekl.execute-api.us-east-1.amazonaws.com";
// ...
Let's build the frontend again with the new endpoint in the config. Don't forget to delete the old build folder and reinstall the frontend packages we deleted previously.
rm -rf build/
yarn
yarn build
serve build/
Visit http://localhost:5000 and make sure Strapi is working as before.
Make a serverless database and file storage
So far we have divided Strapi into two components: 1) a static website frontend and 2) a backend running on Lambda accessible through API Gateway. We will add two additional components. The backend also needs 3) a database and 4) a static file storage for images and other files we upload.
All the components should have the serverless properties. Scalable, pay-per-use, and no touch ops. For static file storage, we will use Amazon S3 file storage, which is not only highly appropriate for the task, but Strapi also comes with a plugin for S3.
The database is more tricky. It's possible to create a DynamoDB connector to Strapi, but that would limit the index flexibility of Strapi, and remove full text search. Let's consider the options.
Databases for Strapi Serverless
DynamoDB does not work with Strapi without a connector we would have to create ourselves.
Aurora is a managed relational database offered by Amazon. It is compatible with PostgreSQL or MySQL. It has a "serverless" configuration setting which enables sleep when inactive and auto scaling. The AWS managed databases like Aurora are only available within a Virtual Private Cloud (VPC). Having our Lambda function in the same VPC means it loses internet access without further configuration and costs, so we won't use that option in this tutorial.
We can use an external database such as Mongo hosted with Mongo Atlas. It is not serverless, but it is managed and possible to scale by just upgrading a subscription. You can also host your own SQL or Mongo instance either in the Amazon cloud or somewhere else.
We don't have a perfect database option for all uses cases. If you use Strapi as a CMS or static sites, the database performance is not a priority at all, so we choose something that is easy to set up and has a free offering. This tutorial will show how to use Mongo Atlas.
Set up Mongo
Just create an account and set up a free Mongo cluster in Atlas for the purpose of this tutorial. You must create a database user with a username and password, then get the connection URI and insert it as an environment variable to our Lambda function.
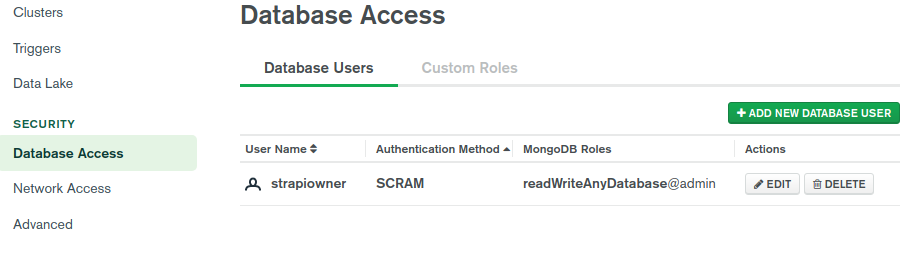
Get the connection URI string in Cluster > Connect > Connect your application.
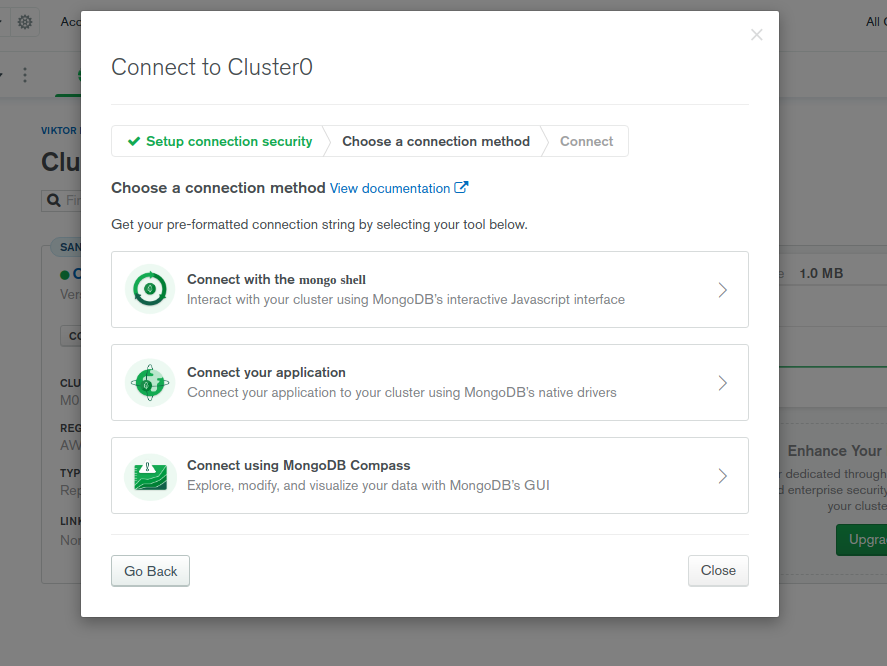
Add the connection URI as an environment variable.
# serverless.yml
provider:
# ...
environment:
MONGODB_URI "mongodb+srv://strapiowner:[email protected]/strapi?retryWrites=true&w=majority"
We then edit config/database.js to tell Strapi to use the Mongo database.
| // config/database.js | |
| const getDatabaseConfig = ({ env }) => { | |
| if ( | |
| env("IS_OFFLINE", null) === "true" || | |
| env("LAMBDA_RUNTIME_DIR", null) === null | |
| ) { | |
| // In local simulated Lambda or normal Strapi | |
| return { | |
| connector: "mongoose", | |
| settings: { | |
| uri: env("MONGODB_URI"), | |
| }, | |
| options: { | |
| ssl: true, | |
| }, | |
| }; | |
| } else { | |
| // In Lambda on AWS | |
| return { | |
| connector: "mongoose", | |
| settings: { | |
| uri: env("MONGODB_URI"), | |
| }, | |
| options: { | |
| ssl: true, | |
| }, | |
| }; | |
| } | |
| }; | |
| module.exports = ({ env }) => ({ | |
| defaultConnection: "default", | |
| connections: { | |
| default: getDatabaseConfig({ env }), | |
| }, | |
| }); |
Lastly, install the Strapi connector for Mongo:
yarn add strapi-connector-mongoose
You can now start Strapi with sls offline and check that it works locally by visiting http://localhost:3000/dev. While it should work i the cloud as well, it's good to double check by deploying with:
yarn && ./scripts/trim-node-modules.sh
sls deploy --verbose
Cloudformation of S3
We create a simple S3 bucket in our Cloudformation templates. An advantage of the Serverless framework is the infrastructure as code comes included to a large degree, so managing resources like S3 buckets is controlled and checked in your Git repo.
We edit the provider, custom, plugins, and resources sections of our serverless.yml config.
| service: sls-strapi | |
| provider: | |
| name: aws | |
| runtime: nodejs12.x | |
| profile: <your-aws-profile> | |
| logRetentionInDays: ${self:custom.vars.logRetentionInDays, 1} | |
| environment: | |
| ADMIN_JWT_SECRET: "Just using dummy" | |
| API_SERVICE_HOST: "https://l4rjveb7rk.execute-api.us-east-1.amazonaws.com/dev" | |
| BUCKET_NAME: !Ref S3StaticBucket | |
| # URL from a free Mongo Atlas cluster. | |
| MONGODB_URI: "mongodb+srv://strapiowner:[email protected]/strapi?retryWrites=true&w=majority" | |
| iamRoleStatements: | |
| - Effect: Allow | |
| Action: | |
| - "s3:*" | |
| Resource: | |
| - !Sub | |
| - "#{BucketArn}/*" | |
| - BucketArn: !GetAtt S3StaticBucket.Arn | |
| - !GetAtt S3StaticBucket.Arn | |
| resources: | |
| Resources: | |
| S3StaticBucket: | |
| Type: AWS::S3::Bucket | |
| custom: | |
| apigwBinary: | |
| types: | |
| - "multipart/form-data" | |
| plugins: | |
| - serverless-offline | |
| - serverless-cloudformation-sub-variables | |
| - serverless-apigw-binary | |
| # ... |
Install the Strapi provider for S3 upload and two other plugins:
yarn add strapi-provider-upload-aws-s3
yarn add -D serverless-apigw-binary
yarn add -D serverless-cloudformation-sub-variables
We need to add some config in a new file called config/plugins.js. S3 in Lambda works quite automagically, so the only config we need is the bucket name. Note that the BUCKET_NAME environment variable will be "Object object" if you run locally with sls offline, because we get the bucket name in serverless.yml with a Cloudformation !Ref. After you deploy, you get the name of your S3 bucket which you can use to test with S3 locally later.
| // config/plugins.js | |
| module.exports = ({ env }) => ({ | |
| upload: { | |
| provider: "aws-s3", | |
| providerOptions: { | |
| params: { | |
| Bucket: env("BUCKET_NAME"), | |
| }, | |
| }, | |
| }, | |
| }); |
To create the S3 bucket, deploy with
./scripts/trim-node-modules.sh
sls deploy --verbose
Once deployed, visit http://localhost:5000 to visit the admin user interface. Go to Media Library and try to upload a file.
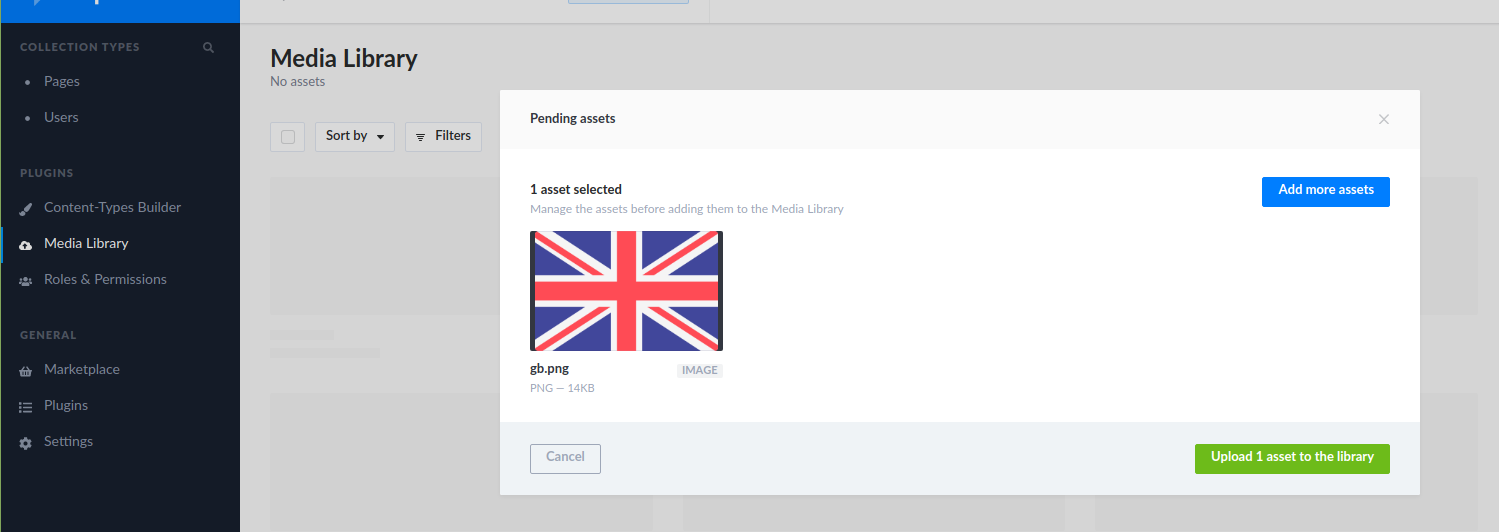
File upload and API Gateway
Uploading files when using Serverless can be a bit of a hassle. All HTTP requests goes through an Amazon service called API Gateway. This gateway processes files in a certain way.
Uploads are often in a binary format, and we need to tell API Gateway explicitly which content types it should handle as binary files.
In Strapi the content type is multipart/form-data, and we configure this with the serverless-apigw-binary plugin. DON'T add "/" as a content-type, as this will break the CORS configuration of your API.
Wrapping up
You know have a scalable Strapi instance that is paid on a pay-per-use basis. Unfortunately, we were not able to make the database as serverless as the rest of the application, but for many use, cases, such as when Strapi is a backend for a CMS to a static site, this is of little significance.
Multi tenancy and Strapi as headless CMS
Strapi does not support multi tenancy. Meaning if you have a portfolio of websites that use Strapi as a CMS, each website needs its own Strapi instance. This is a major weakness of Strapi in my opinion. Wordpress supports multisite config, and many hosting providers have support for unlimited Wordpress instances on a single subscription, which is possible because Wordpress supports multi tenancy.
Many managed CMSs such as Contentful charge on a per user and per project basis. Meaning you have to pay much more once you want people to cooperate on a project or you have many projects.
Our Serverless Strapi allows scalable multi tenancy with Strapi in the following way: Create a new Strapi application for each project just like we did in this tutorial. Let all projects use the same database cluster, but a different database name and user. You can now create hundreds of Strapi APIs using the same fixed cost database. The other costs are S3 file storage, Lambda invocations, and some bandwidth which is billed on a pure pay-per-use basis.
See the Git repo for this tutorial at https://github.com/viktorfa/strapi-serverless.